一、来了一个需求
小Z:https://git.example.com/example-project/xxx.py
求有时间看下 😐,找不到啥原因导致的oom了🤦🏻♀️
二、开始的想法
根据我的经验,将内存泄露问题按照排查手段分为两种。
- 第一种需线上
活体检测,一般是内存泄露难以复现或需要较长时间复现,或线上正在发生问题,需要现场紧急诊断。通常有直接读取程序内存分析和事先在进程中留好后门两种做法。 - 程序可以修改后重新运行,如加入一些诊断代码,然后尝试复现问题。
通常来说,第二种是相对容易排查的,但第一种也胜在有更多的现场信息。
三、跟同事沟通
我问小Z程序还在运行吗?
这个问题回答是,可以登录到机器上观察当前的内存占用状态,程序CPU占用状态,观察一段时间的内存增量。
如果回答否,问题就变的简单了,因为这是一个可以通过修改重新运行程序来定位的内存泄露问题。
小Z回答说程序已经停了。
那这样排查就变得简单起来,跟小X明确了一下部署机器、代码位置、启动命令。
我问小Z可以我运行这个程序吗?确定是否有副作用
可以运行。
四、静态分析代码
新接下来就是排查定位原因了,跟据我的经验,python的内存泄露多数都是因为产生了大量对象,其引用被List或dict所持有。表现为List不停的append数据,或者dict不停的插入数据。那么首先就是要看一下代码中是否写的有问题。
点开代码一看,嚯,看起来代码有上千百行,从程序入口大致看了一下逻辑:这是一个常驻进程,从redis中接收任务命令数据,并通过固定大小的线程池执行任务。
如果想要肉眼快速定位内存泄露的可疑点,而不是修改代码反复运行的话。要从GC的角度考虑。Python作为一门有GC的高级语言,简单来说就是要找到生命周期存活久的对象,然后查看这些对象的属性所占用的内存是否一直在膨胀。膨胀离不开大量对象的创建、循环或递归调用,或者是从外部加载了一个超大数据。
首先要找到生命周期长的对象,首先就是要看全局变量,其次是忽略所有的局部变量,最后是重点关注类属性、函数或方法传递的可变参数。因为不管是List不停的append数据还是dict不停的插入数据,必然有一个存活的比较久的变量指向了这个List或者Dict.
其次是重点关注循环、递归调用以及外部数据的输入。在这个程序中,肉眼并未发现可能出现内存泄露的list和dict, 但是找到了常驻进行的while True循环, 这是一个简便的反复输出进程内存占用的入口点。
肉眼未能定位到泄露原因,接下来采用了使用大杀器,看看网上的快速解决方案。Stack Overflow栈溢出网站肯定能解决我们Python堆溢出的问题。
排名靠前的几个回答,看起来都挺不错,小Z同学也尝试了pympler这个包,发现了String对象占用内存过多,但是未能准确定位到原因。
五、观察进程、确定排查方案
高端的内存泄露定位往往需要只需要最简单的debug方式。
我决定省掉学习新库的成本。采用print调试法,百年传承,百试百灵。
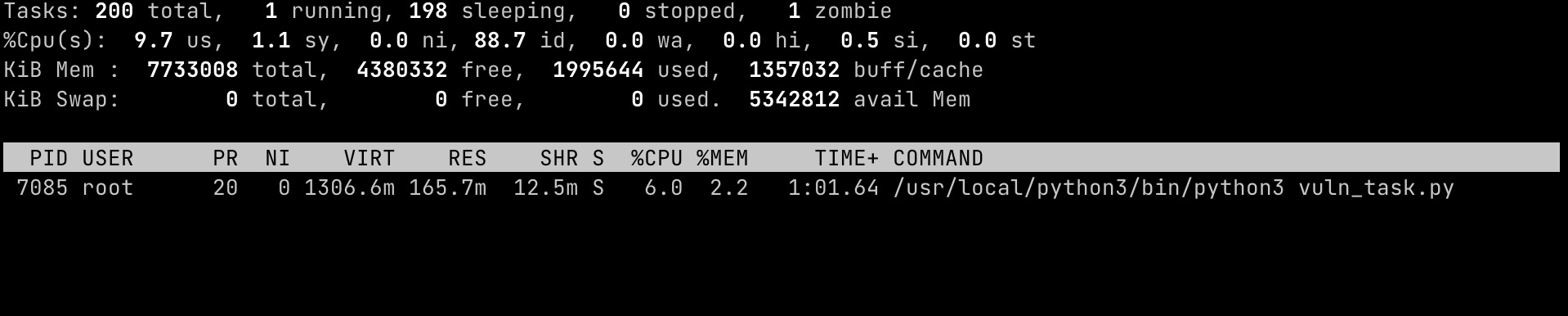
小Z启动了程序xxx.py
这个时候打开一个terminal,输入
top -c -d.5
e
o
COMMAND=vuln
静静的观察几分钟这个程序的内存占用很快的便涨到了1GB,这也意味着这是一个好排查的问题。能够复现问题,已经成功了50%
大家都知道在Python中dict实现是拉链法的哈希表,知道rehash的过程是当哈希表的槽位占用超过2/3后,就扩容至已使用空间大小的4倍,也就是每次rehash以当前大小的267%扩容,当key达到5w个时,以133%的大小进行扩容。
大家也都知道而list的实现就是一组指针列表,其内存分配方式采用如下代码标识
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6)
也就是每次扩容约12.5%的大小。
这两种扩容方式都是基于同一套哲学,一次插入可能是一组插入的开始,为了避免昂贵的系统调用,内存先申请好,提高效率。
但是同样我们也需要知道的是,dict和list中存放的都是指向对象的引用,也就是说其本身占用的内存,其实并不太多, 这也就意味着,如果dict和list的占用内存较大,那一定是其持有了大量的对象引用。简单来说,在python中生成4000w个int对象,约占用1GB的内存。所以内存泄露往往还是因为大量对象被创建,并且被list或dict所持有指向这些对象的引用。
六、上手定位问题
啰嗦了这么多,怎么找到是哪些对象被大量创建了,又被哪些list或dict持有引用了呢?
Python标准库的gc、sys模块提供了检测的能力
import gc
import sys
gc.get_objects() # 返回一个收集器所跟踪的所有对象的列表
gc.get_referrers(*objs) # 返回直接引用任意一个 ojbs 的对象列表
sys.getsizeof() # 返回对象的大小(以字节为单位)。只计算直接分配给对象的内存消耗,不计算它所引用的对象的内存消耗。
我们基于这些函数,先把进程中所有的对象引用拿到,得到对象大小,然后从大到小排序,打印出来,代码如下:
import gc
import sys
def show_memory():
print("*" * 60)
objects_list = []
for obj in gc.get_objects():
size = sys.getsizeof(obj)
objects_list.append((obj, size))
for obj, size in sorted(objects_list, key=lambda x: x[1], reverse=True)[:10]:
print(f"OBJ: {id(obj)}, TYPE: {type(obj)} SIZE: {size/1024/1024:.2f}MB {str(obj)[:100]}")
前面我们找到一个任务执行的while True循环,将show_memory在循环调用即可。
打印的结果较多,取其中一次打印如下
**************************************************
OBJ: 139724853066320, TYPE: list SIZE: 50.63MB ['aa', 'aah', 'aahed', 'aahing', 'aahs', 'aal', 'a
OBJ: 139725115217152, TYPE: dict SIZE: 0.07MB {'__name__': 'lib', '__doc__': None, '__package__'
OBJ: 139725115216512, TYPE: dict SIZE: 0.07MB {'CRYPTOGRAPHY_PACKAGE_VERSION': <cdata 'char *' 0
OBJ: 139724853174096, TYPE: list SIZE: 0.06MB [['str', 31537, 5229883], ['type', 1940, 1791832],
OBJ: 139725332229808, TYPE: dict SIZE: 0.04MB {9133376: <weakref at 0x7f1456cb4770; to 'type' at
OBJ: 139725332425056, TYPE: dict SIZE: 0.04MB {'sys': <module 'sys' (built-in)>, 'builtins': <mo
OBJ: 139724749199472, TYPE: dict SIZE: 0.04MB {'__module__': 'lxml.etree', '__doc__': 'Libxml2 e
OBJ: 139724748735264, TYPE: list SIZE: 0.03MB [(4, 0, 0), (5, 0, 0), (7, 0, 0), (8, 0, 0), (11,
OBJ: 139725331169680, TYPE: dict SIZE: 0.02MB {'__name__': 'os', '__doc__': "OS routines for NT
从打印结果中可以看到,第一个list大小已经达到了50MB, 而这仅仅是list本身的大小,不包括所引用的对象的内存消耗。这时可以认为这个list持有了大量对象,对象类型为字符串。
为了验证其是否持有了大量对象,我打印了这个list的长度,可以看到
LEN: 178758
LEN: 357516
LEN: 536274
LEN: 715032
LEN: 893790
LEN: 1072548
LEN: 1251306
LEN: 1430064
LEN: 1608822
LEN: 1787580
LEN: 1966338
list长度在以178758(17w)个对象的创建速度稳定增长,循环几秒钟一次,内存在不断被占用。
gc.get_referrers(*objs) # 返回直接引用任意一个 ojbs 的对象列表
通过这个函数,我们查询到引用该list的对象信息

输出显示该对象被wordsegment库引用,回到代码中搜索哪里使用到这库,发现只有一个地方使用。
from wordsegment import load,segment
def is_filter_broken_access(self,request):
...
# segment 分词前必须先load
load()
uri_segs = segment(path.split('/')[-1].split('?')[0])
...
显然这里面能够造成问题就只有load()和segment()这两个函数。
查看segment()代码发现,其修改的变量都存在于函数的局部作用域,因此忽略。
查看load()代码发现,该函数有多处修改实例属性的代码,犯罪嫌疑人出现了。
class Segmenter(object):
"""Segmenter
Support for object-oriented programming and customization.
"""
WORDS_FILENAME = op.join(
op.dirname(op.realpath(__file__)),
'words.txt',
)
def __init__(self):
self.words = []
def load(self):
"Load unigram and bigram counts from disk."
with io.open(self.WORDS_FILENAME, encoding='utf-8') as reader:
text = reader.read()
self.words.extend(text.splitlines())
load函数只要多次调用,self.words就会因为加载words.txt中的内容长度不断增加。
查看words.txt 内容为
aa
aah
aahed
aahing
aahs
aal
aalii
aaliis
aals
aardvark
aardvarks
aardwolf
aardwolves
aargh
aarrgh
文件行数为178758 正是大量对象的原始来源。
查看代码可知,库暴露出来的load()函数,实际为非幂等的实例方法,不可以被多次调用, 最好只在程序启动时初始化调用一次。
_segmenter = Segmenter() # pylint: disable=invalid-name
clean = _segmenter.clean # pylint: disable=invalid-name
load = _segmenter.load # pylint: disable=invalid-name
isegment = _segmenter.isegment # pylint: disable=invalid-name
segment = _segmenter.segment # pylint: disable=invalid-name
UNIGRAMS = _segmenter.unigrams
BIGRAMS = _segmenter.bigrams
WORDS = _segmenter.words
至此,可以盖棺定论了。load()将有权保持沉默,沉默是今晚的康桥。
将load() 方法调用修改为仅调用一次后,启动程序,内存稳定,不再快速增长。
七、总结
根据我的经验,Python的内存泄露可总结为以下公式
循环对象创建 + 引用收敛 + 长对象生命周期 = 内存泄露
- 循环可以是while true也可以是迭代或者web服务
- 引用收敛通常会集中到list或dict这类可变容器类对象中
- 长对象生命周期往往是全局变量或长期存活的实例变量。
- 对象创建往往是外部输入触发的,如请求数据库、加载文件等。
这次的排查较为简单,通过python标准库即可完成。完全基于标准库对于一些不能随意改动的线上环境场景调试十分有用。
八、One more thing...
对于另一种内存泄露在线上进程进程活体检测 场景,其实是个手艺活,往往是问题正在发生需要到正在运行的进程内一探究竟,这样就需要用到 动态追踪技术 这里不进行展开。对于python来说,我推荐 py-spy 这个非常好用的生产环境活体检测工具,可以仅在略微影响程序性能的情况下dump堆栈信息、生成火焰图、实时查看代码执行CPU占用耗时,可谓Python届“居家旅行殺人滅口必備良藥”。
EOF